Zkoušení slovíček
Slovní zásoba je určitě jednou z nejdůležitějších věcí, kterou se student cizího jazyka musí naučit. Bez správné gramatiky se komunikovat dá, sice možná někdy těžko, ale dá. Bez správné výslovnosti či pravopisu určitě také. Bez slovíček se ale prostě nedomluvíte vůbec. Možná proto se na slovní zásobu klade největší důraz.
Jak se ale slovíčka učit? Memorovat se seznamy slov, kde je na jedné straně slovo anglicky a na druhé česky? Nebo si vytvořit kartičky a učit se je při chození po místnosti tam a zpět? Pustit si při jízdě autem nahrávku, kde někdo takový seznam přeříkává nahlas, dog, pes, house, dům, nechat se někým “zkoušet”?
Každému jistě vyhovuje při učení slovíček něco jiného.
My jsme vytvořili způsob učení a procvičování, který skvěle funguje jak pro učení úplně nových slovíček, tak pro opakování již naučených. Jak funguje? Vyberete si nějaký okruh slovní zásoby a nebo si ho sami vytvoříte a program vás potom zkouší, dokud se všechna zvolená anglická slovíčka nenaučíte.
Celý cyklus zkoušení potom spočívá v tom, že vám program předkládá slovíčka z daného okruhu. Pokud odpovíte špatně, zařadí ho zpět do zkoušení a slovíčko se bude opakovat častěji, pokud odpovíte správně, slovíčko se ze zkoušení postupně vyřadí.
Představte si celý systém jako sadu pěti krabiček.
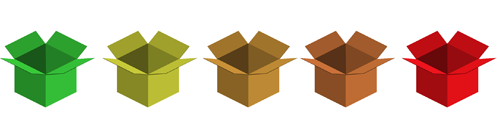
V první krabičce jsou slovíčka, která skvěle ovládám, v poslední jsou slovíčka, která vůbec neumím.
Když začne zkoušení, všechna slovíčka jsou umístěna v jakési šedé krabičce (tam jsou všechna slovíčka, která ještě ve zkoušení nebyla). Pro ilustraci budeme pracovat s šesti slovíčky označující zvířata:
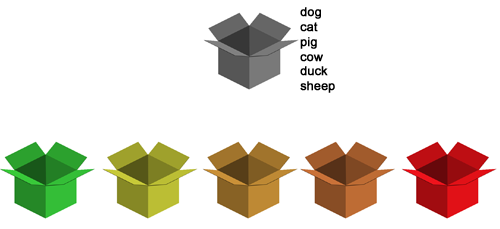
Počítač náhodným výběrem vytáhne z šedivé krabičky např. slovíčko cat. Odpovíme-li dobře, počítač slovíčko zařadí hned do druhé krabičky, protože se zdá, že toto slovo známe.
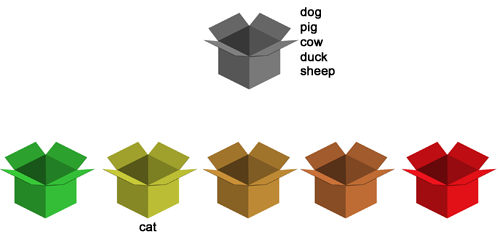
Nyní počítač vybere další nové slovíčko z šedivé krabičky nahoře, např. slovo dog. Odpovíme špatně, nebo prostě nevíme a bez hádání, stiskneme rovnou klávesu ENTER. Počítač nám sdělí, jak mělo slovíčko správně znít, ukáže nám k tomu obrázek, definici, výslovnost atd. Tento moment je klíčový. Zde by mělo proběhnout takové to ‘Aha! Takhle to tedy je!’ Protože jsme slovo neuměli, slovíčko putuje do krabičky č. 4.
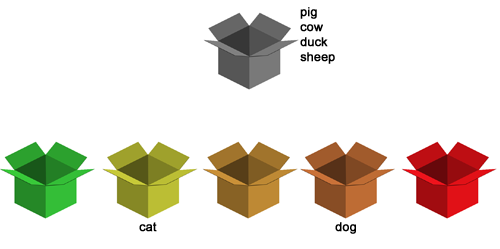
Takto tedy funguje rozřazování z šedivé krabičky vždy. Znám → krabička č. 2, neznám → krabička č. 4.
Princip dalšího zkoušení je, že počítač se bude snažit co nejdříve zopakovat slovíčka, která neznám. Přednost mají vždy slovíčka, co jsou v krabičkách dále. V tuto chvíli, protože jediné slovíčko, které neznám, je dog, by počítač chtěl sáhnout opět po slovíčku dog, ale to mu nedovolíme. Slovíčko má teď člověk uložené jen v krátkodobé paměti (před zlomkem vteřiny ho viděl). Trochu tedy počkáme, aby se zjistilo, zda slovíčko vážně nezná a nebo jestli se třeba jednalo jen o překlep apod. Počítač tedy mezi tím postupně vybere několik slovíček z šedé krabičky. Např. sheep, duck, která zadám správně a pošlu je tak ke kočce do druhé krabičky, a cow, kde udělám chybu a to se přesune do krabičky č. 4.
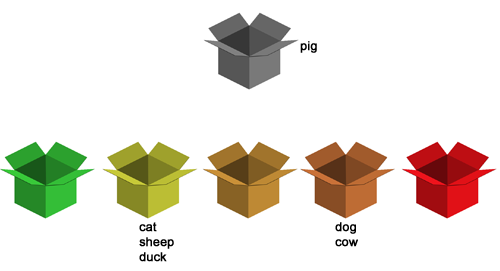
Protože od posledního použití dog, které je ve čtvrté krabičce, proběhlo několik dalších slov, je čas slovíčko vrátit. Tentokrát na něj již odpovíme správně. Slovíčko tedy přejde o jednu krabičku výš, tedy do krabičky č. 3.
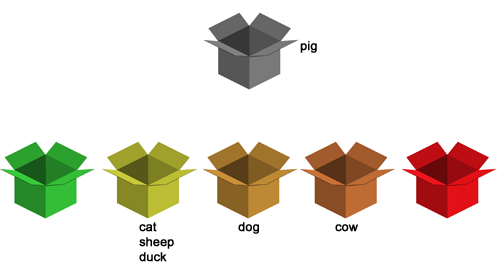
Potřebujeme se tedy stále naučit slovíčka dog a cow. Ani jedno v tuto chvíli ještě nemůže padnout, aby se slova neopakovala moc brzy po sobě. Proto počítač vezme další slovíčko z šedé krabičky, které ještě nebylo. Bude to slovíčko pig. Uděláme v něm chybu, přesune se tedy do krabičky č. 4.
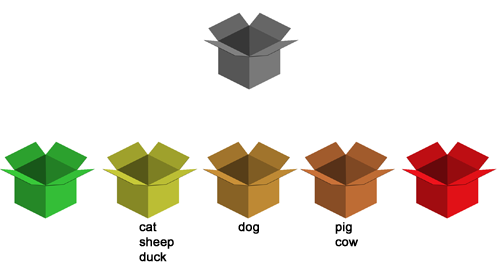
Nyní přichází už čas na slovíčko cow, protože je v nejnižší krabičce a od posledního opakování proběhla již alespoň dvě slova. Opět ale ve slovíčku udělám chybu, stále ho neumím, a to se propadne úplně do nejnižší krabičky.
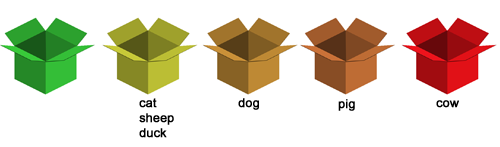
Protože se jedná už o druhé chybné zadání, počítač toto slovíčko vyhodnotí jako velmi problematické, a proto ho předloží ihned znovu do zkoušení. Slovíčko by měl mít člověk zapsané v krátkodobé paměti, tedy měl by ho být schopen napsat správně. Pokud ne, program ho bude opakovat tak dlouho, dokud ho nezadáme správně. Potom se vrátí do krabičky č. 4.
Nyní zkoušení pokračuje dál. Počítač vybírá slovíčka z nejnižších krabiček a aby zabránil častému opakování, vždy je prokládá slovíčky z vyšších krabiček. Stále platí pravidlo: Správná odpověď znamená postup o jednu krabičku výš, špatná odpověď znamená propad o jednu krabičku níž.
Kdy končí zkoušení?
V aplikaci máme dvě možnosti, normální a důkladné. Které preferujete, si můžete zvolit v nastavení aplikace (ikonka ozubeného kolečka, položka Nastavení, záložka Zkoušení slovíček, položka Důkladnost zkoušení).
Normální zkoušení končí, když jsou všechna slovíčka ve druhé krabičce a nebo výš. Pokud bychom zadali všechna slova správně, každé by se tedy objevilo pouze jednou. Protože jsme ale dělali chyby, může závěrečné rozvržení slovíček v krabičkách vypadat např. takto:
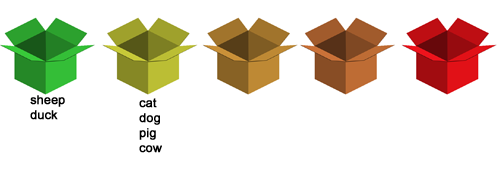
Každé slovíčko jsme zadali minimálně jednou správně, pokud jsme ve slově udělali chybu, zadali jsme ho potom minimálně dvakrát správně.
Druhá možnost, důkladné zkoušení, končí v moment, když jsou všechna slovíčka v první krabičce.
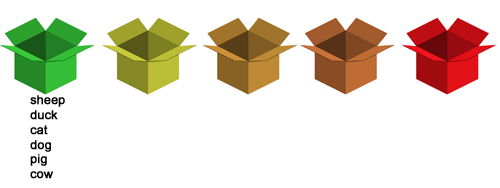
Tedy každé slovo musím napsat správně minimálně dvakrát, problematická minimálně třikrát, velmi problematická minimálně čtyřikrát.
Odstranění slovíčka ze zkoušení
Pokud v daném zkoušení objevíte slovíčko, které se z nějakého důvodu nechcete učit, nebo se jedná o slovíčko, které nelze rozeznat od jiného slovíčka ve zkoušení, je možné takové slovíčko odstranit. Po napsání odpovědi je v pravém dolním roku ikonka koše. Pokud na ni kliknete a potvrdíte odstranění slovíčka, toto slovo se z celého cyklu zcela odstraní. Nebude se tedy již vracet až do konce aktivity. Slovíčko se však nesmaže z okruhů slovní zásoby. Při opětovném spuštění aktivity tedy slovíčko opět ve zkoušení bude zařazeno.
Zkoušení bez psaní na klávesnici
Pokud jste si zvolili způsob zkoušení bez psaní na klávesnici, student si odpovědi pouze říká nahlas nebo v duchu. Počítač samozřejmě nepozná, zda odpověděl správně či nikoliv. Zhodnotit se a porovnat svoji odpověď s tou, kterou počítač zobrazí, ale určitě nikomu problém nebude dělat. Naše “krabičková metoda” funguje i zde úplně stejně, tedy s jedním malým rozdílem. Student tu má kromě klasického správně / špatně také možnost ok.
Tu může student využít, když má pocit, že řekl třeba slovíčko jiné, které je ale také správně. Neznamená to ale, že by to byla chyba. V takovém případě slovíčko zůstává v krabičce, ve které bylo, tedy neposouvá se nahoru ani dolů.
Rozpoznávání synonym
Někdy se stane, že člověk odpoví slovíčkem, které počítač nepožaduje (nejedná se o slovíčko ve vybraném okruhu), ale přesto je víceméně přijatelné (např. se jedná o synonymum). Pokud tedy napíšete místo advice slovíčko tip, počítač odpověď nebude vyhodnocovat. Pouze sdělí, že očekával jinou odpověď a uživatel se má pokusit odpovědět jinak.
Proč synonymum prostě neuzná jako správnou odpověď? Domníváme se, že student má v okruhu právě ta slovíčka, která se chce naučit. Pokud má v okruhu slovíčko advice, chce se naučit právě to. Pokud bychom jako správné přijali i tip, zkoušení by skončilo, aniž by se student naučil slovíčko advice.
Důležité je, že nejde o zkoušení slovíček “u tabule”, ale o proces učení. Počítač má zadaná slovíčka, která vás má naučit, a bere to vážně.
Důkladnost ‘každé slovíčko pouze jednou’
V nastavení zkoušení lze zvolit kromě normálního a důkladného ještě jednu možnost – Každé slovíčko pouze jednou. Takové zkoušení nepoužívá ‘krabičkovou metodu’, ale pouze projde všechna slovíčka z okruhu jednou, bez ohledu na to, zda je zadáte správně či špatně.
Toto zkoušení je ideální např. na seznámení s okruhem či na to, abyste si nejprve roztřídili slova na problematická a neproblematická, a potom si spustili zkoušení těch problematických nějakým důkladnějším způsobem.
Chytré opakování aneb spaced-repetition
Určitě není možné naučit se takto jednou slovíčka a potom očekávat, že si je budu vždy pamatovat. Proto jsme vytvořili systém chytrého opakování, které je založené na algoritmu SRS – Spaced Repetition System. Ten zaručí, že aplikace vám slovíčko připomene v tu chvíli, kdy byste ho už jinak mohli zapomenout.